Septembre 20, 2024
HeitaDeals
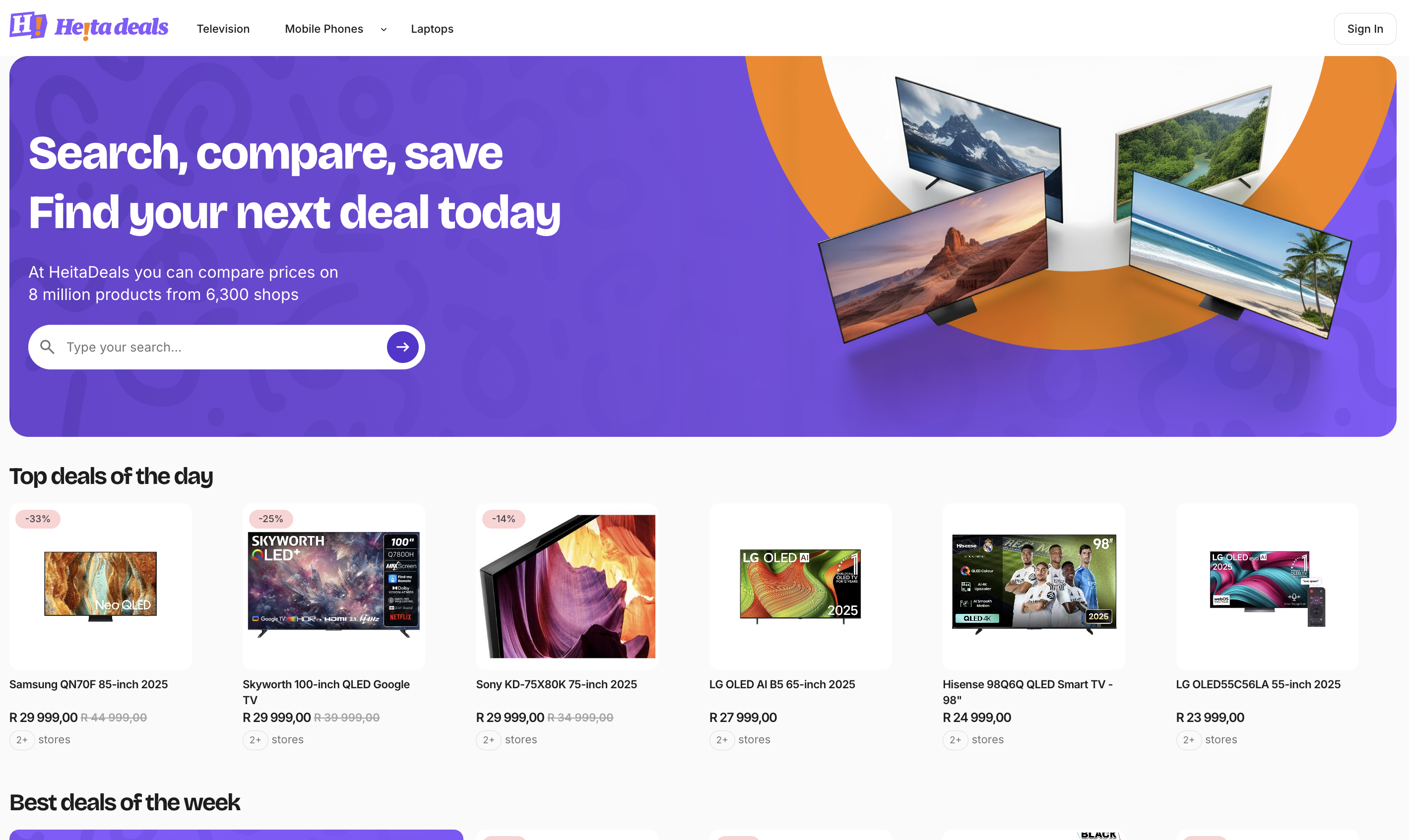
HeitaDeals is a website that helps people in South Africa compare prices and find good deals. It collects prices from many online shops and shows how prices change over time. Users can make boards to save products they like, share them with friends, and talk or react under each product to help each other choose what to buy.
Core Problem
Online shoppers in South Africa spend a lot of time visiting many stores to compare prices. Prices change often and it is hard to track the best offers. People also want to decide with friends but there is no simple way to share and discuss products while watching price changes.
Core Features
- Price Comparison: See prices for the same product from many online stores in one place.
- Price History: View simple charts that show how the price has changed over time.
- Boards: Create your own boards to save and organize products you like.
- Sharing: Share your boards with friends so you can look at products together.
- Reactions and Comments: React to products and write comments to share your thoughts.
- Real-Time Chat: Talk with your friends under each product using live chat powered by Supabase.
My Role and Contributions
I worked as a full-stack developer, focusing on the frontend and part of the backend. I used Next.js for the web interface and Supabase for the database, authentication, storage, and real-time features.
We built the web crawlers using Python, Redis, and Flower to collect product data from many online stores. Each crawler could be configured using a JSON file that defined how to get product data, handle pagination, or run JavaScript if needed. The crawlers were containerized with Docker and hosted on AWS, where I set up schedulers to run them automatically every 24 or 48 hours to keep data fresh.
After collecting data, We cleaned the HTML to keep only useful text and built a batch system that sends data to OpenAI for product information extraction. I also handled data merging to add or update products in the database and keep product attributes consistent with lookup tables.
We developed a scoring and ranking system that used product quality, data accuracy, and pricing to decide how products appear in search results.
For social features, I built real-time reactions and chat using Supabase Realtime, with a local message cache for faster and smoother interactions.
I also used embeddings and NLP to detect duplicate or similar products from different sellers, allowing the site to display all prices for one product and suggest related items. The frontend was built as a data-driven system, where new pages could be created from JSON files without changing the code.
Technical Architecture
- Frontend: Built with Next.js, connected to Supabase for authentication, database access, and real-time updates.
- Database: Supabase stores users, products, boards, chats, and prices, with lookup tables for consistent attributes.
- Backend and Crawlers: Python + Redis + Flower, containerized with Docker and hosted on AWS. Crawlers run automatically on schedules to keep data updated.
- Batch System: Cleans and sends product data to OpenAI for text extraction.
- Embeddings & NLP: Detect similar and duplicate products for merging and related recommendations.
- Scoring System: Ranks products based on price, quality, and data completeness.
- Data-Driven UI: JSON files define new pages and layouts for easy maintenance.
Challenges and Solutions
- Data Quality and Consistency: Different stores format product data differently, making it hard to compare. We solved this by cleaning HTML, using OpenAI for structured extraction, and implementing lookup tables to standardize attributes like brand, category, and specifications.
- Duplicate Product Detection: Same products from different sellers appeared as separate items. We used embeddings and NLP to detect similar products, allowing automatic merging and unified price displays.
- Real-Time Performance: Real-time chat and reactions needed to be fast and smooth. We implemented a local message cache and optimized Supabase Realtime subscriptions to reduce latency and improve user experience.
- Scalable Crawler System: Managing multiple crawlers for different stores was complex. We containerized crawlers with Docker, used JSON configuration files for easy setup, and automated scheduling on AWS to keep data fresh without manual intervention.
- Search Relevance: Showing the best products first required smart ranking. We built a scoring system that considers price competitiveness, data completeness, and product quality to surface the most relevant results.
- Maintainable Frontend: Adding new features or pages required code changes. We created a data-driven UI system where JSON files define pages and layouts, allowing non-developers to update content without touching code.
Team Collaboration
Our team worked closely with clear roles. The designer handled UI/UX, another teammate managed database design, and I focused on the frontend and backend crawler systems. We used GitHub for version control, Discord for communication, and Notion for task tracking. Collaboration between design, backend, and frontend ensured a consistent and working product.
Impact / Results
HeitaDeals helps users save time by comparing prices from many shops in one place. The boards, chat, and reactions make shopping social and collaborative. The crawler and batch system collected and processed large amounts of data efficiently, while the scoring and ranking system made search results more useful. The embedding system improved product matching, and the data-driven frontend made the platform flexible and easier to maintain.
Future Improvements
- Handle more protected websites using browser-based crawling.
- Improve product matching accuracy using advanced NLP.
- Add price alerts and deeper analytics.
- Expand social features for boards and interactions.
- Add AI-driven recommendations.
- Scale backend and improve automation with better crawler monitoring.
Key Takeaways / Lessons Learned
- Data-driven architectures reduce maintenance overhead and enable non-technical team members to contribute content.
- Containerization and configuration files make complex systems like multi-store crawlers much easier to manage and scale.
- Local caching is essential for real-time features to feel responsive, even with fast backend services.
- Embeddings and NLP can solve complex matching problems that would be difficult with traditional rule-based approaches.
- Clear team roles and good communication tools (GitHub, Discord, Notion) are crucial for distributed development.
- Building flexible, configurable systems upfront saves time when requirements change or new features are needed.
